k8s记录
先留一个坑
01.你为什么需要学习K8S - 掘金 (juejin.cn)
docker
- 基于linux的cgroup、namespace以及union FS 等技术,对进程进行封装隔离,属于操作系统层面的虚拟技术,由于隔离隔离的进程独立于宿主机和其他的隔离进程,因此也成为容器
- docker在容器的基础上,进行了进一步的封装,从文件系统、网络互连到进程隔离等等,极大的简化了容器的创建和维护,使得docker技术比虚拟机更加轻便、快捷
namespace做隔离、cgroups做限制、rootfs做文件系统
为什么要使用docker
- 更高效利用系统资源
- 更快的启动时间
- 一致的运行环境
- 持续交付和部署
- 更加轻松的迁移
- 更加容易维护和扩展
容器的核心技术,就是通过约束和修改进程的动态表现,从而为其创造一个“边界”
对于docker 等大多数linux容器来说,cgroups是用制造约束的主要手段;namespace是用来修改进程视图的主要方法。
namespace
使用 docker run -it busybox /bin/sh ,进入终端,键入ps,发现
1 | |
这种机制就是 对被隔离的应用做了手脚,使得这些进程只能看到重新计算过的进程编号,比如PID=1。可实际上在宿主机可能是PID=100。
除了PID Namespace,Linux提供 Mount、UTS、IPC、Network和User这些 Namespace,对于不同的进程上下文进行障眼法。比如:mount Namespace 用于让被隔离进程只看到当前Namespace里的挂载信息;Network Namespace 只让被隔离进程看到当前 Namespace 里的网络设备和配置。
创建容器进程时,指定了这个进程所需要的一组Namespace,用于被隔离的进程只能够看到当前Namespace里的网络设备和配置。
所以说,容器是一个特殊的进程。
容器和虚拟机的区别:
- 虚拟机通过硬件虚拟化,模拟出一个OS所需要的各种硬件,比如CPU、内存、I\O设备等,通过虚拟的硬件安装一个新的OS;使用虚拟化技术作为应用盲盒,就必须由hypervisor来负责创建虚拟机,这个虚拟机是真实存在的,并且它里面必须允许完整的 guest OS 才能执行用户的应用进程,这就不可避免的带来了额外的性能损失和资源占用
- docker项目帮助用户启动的,还是原来的应用进程,只不过在创建这些进程时,docker为他们加上了各种各样的Namespace参数。此时这些进程就会认为自己是pid为1 的进程,只能看到 mount Namespace里挂载的目录和文件,只能访问network namespace里的网络设备,就仿佛运行在一个 容器里面,与世隔绝;容器化的应用依旧是 宿主机上的普通进程;使用namespace作为隔离手段的容器并不需要但难度的guest os,这使得容器占用的资源可以忽略不计;总结:敏捷,高性能
有利就有弊:基于linux namespace的隔离机制相比于虚拟化技术也有很多不足之处;隔离的不彻底
首先,既然容器只是运行在宿主机上的一种特殊的进程,那么多个容器之间使用的就还是同一个宿主机的操作系统内核。
尽管你可以在容器里通过Mount Namespace单独挂载其他不同版本的操作系统文件,比如CentOS或者Ubuntu,但这并不能改变共享宿主机内核的事实。这意味着,如果你要在Windows宿主机上运行Linux容器,或者在低版本的Linux宿主机上运行高版本的Linux容器,都是行不通的。
而相比之下,拥有硬件虚拟化技术和独立Guest OS的虚拟机就要方便得多了。最极端的例子是,Microsoft的云计算平台Azure,实际上就是运行在Windows服务器集群上的,但这并不妨碍你在它上面创建各种Linux虚拟机出来。
cgroups
control group 实现了资源的限制
rootfs
docker 的网络模式
- bridge: docker 的默认网络模式是bridge;容器通过虚拟的桥和
docker0相连,docker0和主机相连
1 | |
kubernetes
google 开源的,用go实现的,用于管理多主机上的容器,用于自动部署、扩展和管理的应用程序。
运行在大规模集群中的各种任务之间,实际上存在着各种各样的关系。这些关系的处理,才是作业编排和管理系统中最终重要的
编排、调度、容器云、集群管理
路由网关、水平扩展、监控、备份、灾难恢复
基本组件
Master负责管理集群。master节点上包含以上组件
- kube-apiServer:集群的控制入口,提供http rest服务
- etcd:用于保存集群中的工作状态
- kube-controller-manager:集群中的资源控制中心
- kube-scheduler:负责pod的调度
Node是kubernetes集群中的工作节点,Node上的工作负载由master节点分配。工作负载主要是运行容器应用。其中包含一下组件
- kubelet:负责pod的创建、启动、监控、重启、销毁等工作。同时与master节点协作,实现集群的管理
- kube-proxy:实现kubernetes service的通信和负载均衡
- 运行pod
ReplicaSet:是 Pod 副本的抽象,用于解决 Pod 的扩容和伸缩
deployment:表示部署,在内部使用replicaSet来实现。
Service:Service 是 Kubernetes 最重要的资源对象。Kubernetes 中的 Service 对象可以对应微服务架构中的微服务。Service 定义了服务的访问入口,服务的调用者通过这个地址访问 Service 后端的 Pod 副本实例。Service 通过 Label Selector 同后端的 Pod 副本建立关系,Deployment 保证后端Pod 副本的数量,也就是保证服务的伸缩性。
pod里的容器共享一个network namespace、同一组数据卷、从而达到高效率交换信息的目的。
建议 one-container-per-pod
若需要共享某些资源,需要紧耦合。可以多个容器部署在同一个pod中,容器中通过
pause这个容器共享资源。
rc(replication control)、rs(replication set)

service是一种抽象的对象,它定义了一组pod的逻辑集合和一个它用于访问他们的策略。一个service下的pod由lable selector 来决定
三种IP地址
node ipk8s集群中节点的物理网卡IP地址pod ippod的ip地址cluster ipservice 的ip地址
控制器
deployment
- 创建rs、pod
- 滚动升级、回滚
- 平滑扩缩容
- 暂停和恢复 deployment
有状态服务 statefulSet
对于有状态服务进行部署的控制器
稳定的持久化存储
有序部署、有序扩展、有序收缩、有序删除
由 Headless service(有状态服务的DNS管理)、volumeClaimTemplate 组成
它提供了稳定的网络标识符、有序部署和扩展、持久化存储等功能,为有状态服务的部署和管理提供了便利和保障。
deamonSet 为匹配到的每个Node上都部署一个守护进程,常用来部署一些集群的日志、监控和其它管理应用
- 日志收集:logstash
- 监控系统:Prometheus
- 系统程序:kube-proxy、kube-dsn
job
cronJob

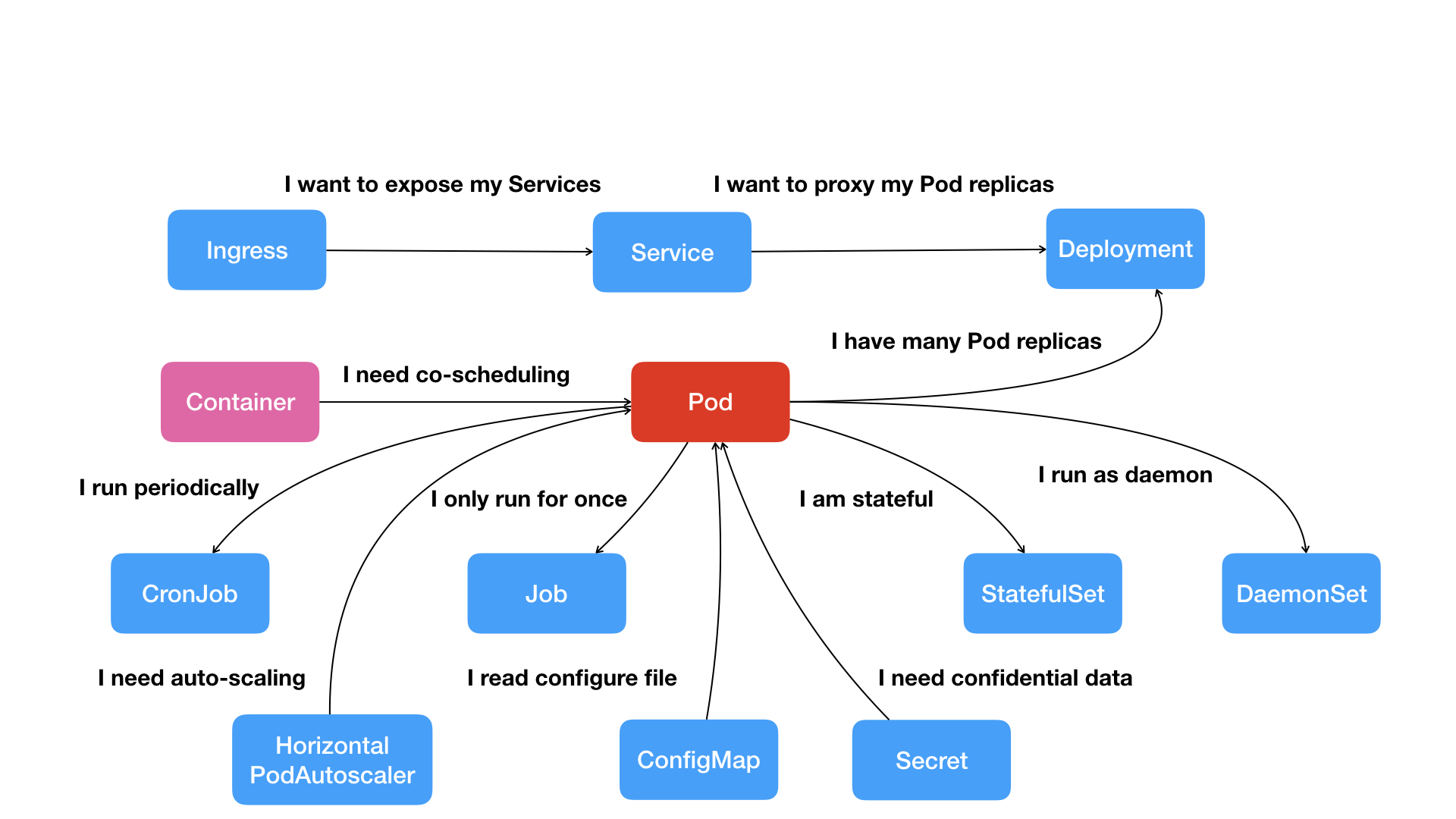
架构图

pod 是kubenetetes中最小单元的API对象;pod是k8s项目中的原子调度单位
对于同一个pod里的用户容器来说,进出流量由Infra容器完成
探针
Liveness 探针用于确定容器是否处于运行状态,当探针失败时会触发容器的重启Readiness 就绪探针
service

pod
pod 的基本概念
pod是一组紧密关联的容器集合,它们共享 PID、IPC、NetWork和UTS namespace,是k8s的基本调度单位。pod的设计理念是支持多个容器在一个pod中共享网络和文件系统,可以通过进程间通信和文件共享这种简单高效的方式完成服务。
其实 Pod 也只是一个逻辑概念,真正起作用的还是 Linux 容器的 Namespace 和 Cgroup 这两个最基本的概念,Pod 被创建出来其实是一组共享了一些资源的容器而已。
创建 pod
1 | |
pod的探针
种类
- startupProbe,但配置了 startProbe后,会先禁用 其他探针,直到容器启动成功。 用来测试 检测容器是否启动完成。
- livenessProbe 检测pod的存活状态;liveness 拥有自愈能力,但容器出现不可恢复的错误时,能自动重启容器。
- readinessProbe 检测是否启动成功,可以接受外部流量。其关注的是 瞬时间的状态。
探测方式
- execAction
- tcpSocketAction
- HTTPGetAction
参数配置
- initDelaySeconds 初始化1时间
- timeOutSeconds 超时时间
- periodSecond 检测间隔时间
- successThreshold 表示成功多少次就表示成功
- failureThreshold 表示失败多少次就失败
1 | |
容器的生命周期
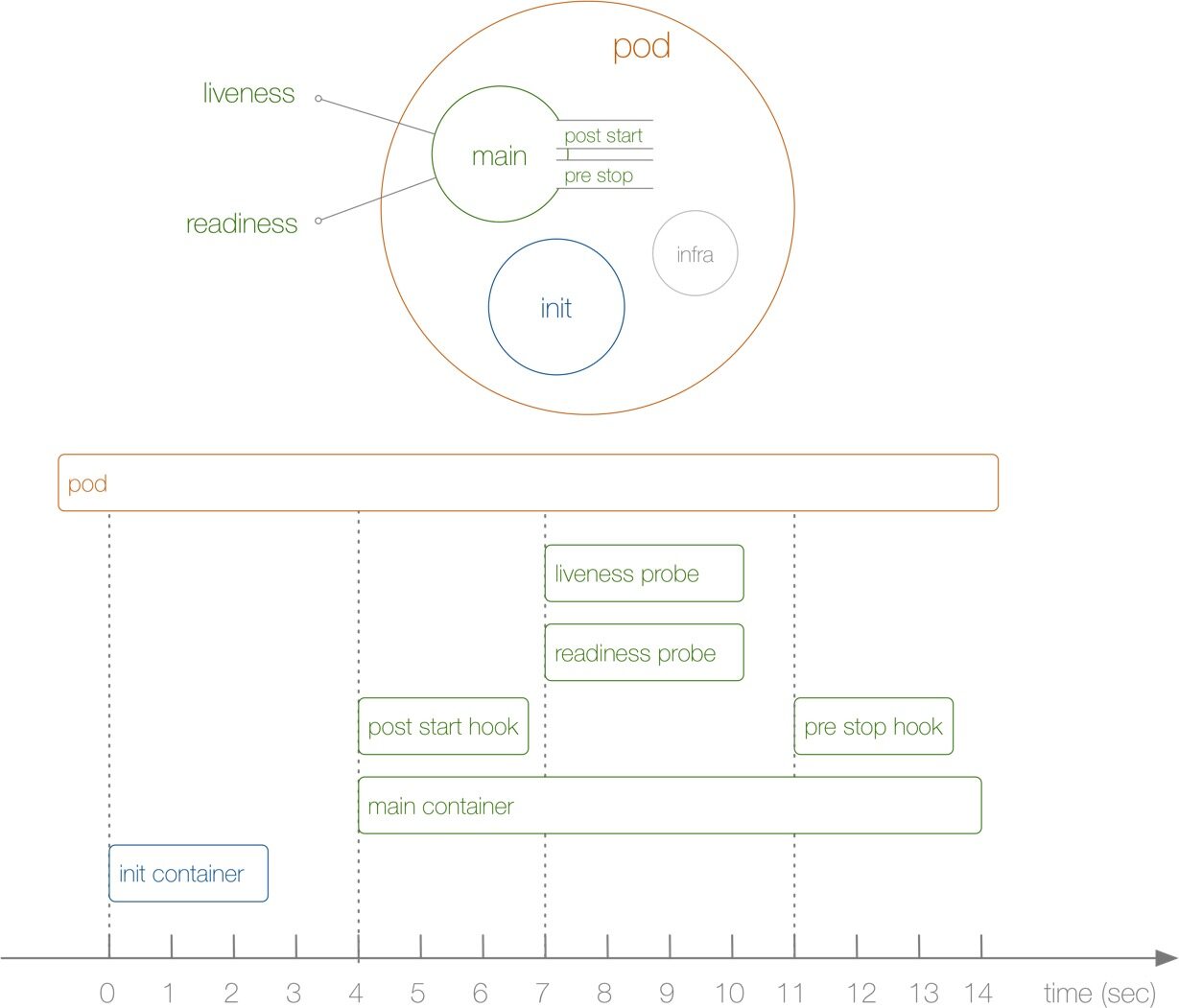

重启策略
- never
- Onfailure
- always
- 不同类型的的控制器可以控制 Pod 的重启策略:
Job:适用于一次性任务如批量计算,任务结束后 Pod 会被此类控制器清除。Job 的重启策略只能是"OnFailure"或者"Never"。ReplicaSet、Deployment:此类控制器希望 Pod 一直运行下去,它们的重启策略只能是"Always"。DaemonSet:每个节点上启动一个 Pod,很明显此类控制器的重启策略也应该是"Always"。
状态
- 挂起(Pending):Pod 信息已经提交给了集群,但是还没有被调度器调度到合适的节点或者 Pod 里的镜像正在下载
- 运行中(Running):该 Pod 已经绑定到了一个节点上,Pod 中所有的容器都已被创建。至少有一个容器正在运行,或者正处于启动或重启状态
- 成功(Succeeded):Pod 中的所有容器都被成功终止,并且不会再重启
- 失败(Failed):Pod 中的所有post容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非
0状态退出或者被系统终止 - 未知(Unknown):因为某些原因无法取得 Pod 的状态,通常是因为与 Pod 所在主机通信失败导致的
preStop
1 | |
金丝雀发布
label和selector
1 | |
1 | |
K8S 的资源清单
| 参数名 | 类型 | 字段说明 |
|---|---|---|
| apiVersion | String | K8S APl 的版本,可以用 kubectl api versions 命令查询 |
| kind | String | yam 文件定义的资源类型和角色 |
| metadata | Object | 元数据对象,下面是它的属性 |
| metadata.name | String | 元数据对象的名字,比如 pod 的名字 |
| metadata.namespace | String | 元数据对象的命名空间 |
| Spec | Object | 详细定义对象 |
| spec.containers[] | list | 定义 Spec 对象的容器列表 |
| spec.containers[].name | String | 为列表中的某个容器定义名称 |
| spec.containers[].image | String | 为列表中的某个容器定义需要的镜像名称 |
| spec.containers[].imagePullPolicy | string | 定义镜像拉取策略,有 Always、Never、IfNotPresent 三个值可选 - Always(默认):意思是每次都尝试重新拉取镜像 - Never:表示仅适用本地镜像 - IfNotPresent:如果本地有镜像就使用本地镜像,没有就拉取在线镜像。 |
| spec.containers[].command[] | list | 指定容器启动命令,因为是数组可以指定多个,不指定则使用镜像打包时使用的启动命令。 |
| spec.containers[].args[] | list | 指定容器启动命令参数,因为是数组可以指定多个。 |
| spec.containers[].workingDir | string | 指定容器的工作目录 |
| spec.containers[].volumeMounts[] | list | 指定容器内部的存储卷配置 |
| spec.containers[].volumeMounts[].name | string | 指定可以被容器挂载的存储卷的名称 |
| spec.containers[].volumeMounts[].mountPath | string | 指定可以被容器挂载的存储卷的路径 |
| spec.containers[].volumeMounts[].readOnly | string | 设置存储卷路径的读写模式,ture 或者 false,默认是读写模式 |
| spec.containers[].ports[] | list | 指定容器需要用到的端口列表 |
| spec.containers[].ports[].name | string | 指定端口的名称 |
| spec.containers[].ports[].containerPort | string | 指定容器需要监听的端口号 |
| spec.containers[].ports[].hostPort | string | 指定容器所在主机需要监听的端口号,默认跟上面 containerPort 相同,注意设置了 hostPort 同一台主机无法启动该容器的相同副本(因为主机的端口号不能相同,这样会冲突) |
| spec.containers[].ports[].protocol | string | 指定端口协议,支持 TCP 和 UDP,默认值为 TCP |
| spec.containers[].env[] | list | 指定容器运行前需设置的环境变量列表 |
| spec.containers[].env[].name | string | 指定环境变量名称 |
| spec.containers[].env[].value | string | 指定环境变量值 |
| spec.containers[].resources | Object | 指定资源限制和资源请求的值(这里开始就是设置容器的资源上限) |
| spec.containers[].resources.limits | Object | 指定设置容器运行时资源的运行上限 |
| spec.containers[].resources.limits.cpu | string | 指定 CPU 的限制,单位为 Core 数,将用于 docker run –cpu-shares 参数 |
| spec.containers[].resources.limits.memory | string | 指定 mem 内存的限制,单位为 MIB、GiB |
| spec.containers[].resources.requests | Object | 指定容器启动和调度时的限制设置 |
| spec.containers[].resources.requests.cpu | string | CPU请求,单位为core数,容器启动时初始化可用数量 |
| spec.containers[].resources.requests.memory | string | 内存请求,单位为MIB、GiB,容器启动的初始化可用数量 |
| spec.restartPolicy | string | 定义 pod 的重启策略,可选值为 Always、OnFailure、Never,默认值为 Always。 - Always:pod 一旦终止运行,则无论容器是如何终止的,kubelet 服务都将重启它。 - OnFailure:只有 pod 以非零退出码终止时,kubelet 才会重启该容器。如果容器正常结束(退出码为0),则 kubectl 将不会重启它。 - Never:Pod 终止后,kubelet 将退出码报告给 master,不会重启该 pod |
| spec.nodeSelector | Object | 定义 Node 的 label 过滤标签,以 key:value 格式指定 |
| spec.imagePullSecrets | Object | 定义 pull 镜像时使用 secret 名称,以 name:secretkey 格式指定 |
| spec.hostNetwork | Boolean | 定义是否使用主机网络模式,默认值为 false。设置 true 表示使用宿主机网络,不使用 docker 网桥,同时设置了 true将无法在同一台宿主机上启动第二个副本 |
Deployment
创建一个pod
1 | |
yaml
1 | |
kubectl edit deploy
滚动更新
1 | |
回滚版本
1 | |
扩缩容
1 | |
statefulSet
无状态应用是 对本地环境没有依赖,可以随意扩容
todo 报错了
1 | |
1 | |
金丝雀发布
1 | |
设置 rollout 中的partition
deaonSet
deamonSet为每个匹配到的 node 部署一个守护进程
案例:
电商场景中多个微服务的调用链可能出现 问题。需要检查日志时,需要登录到每个node节点上,查看相应pod的日志信息。此时,我们可以为每个node部署一个守护进程,例如 flunted来收集日志信息,最后可以发送给 es进行存储。
1 | |
HPA
horizontal-pod-autoScaler-sync-period
service
ingress
外部服务的统一入口
安装 helm
1 | |
流量的转发过程
- 客户端发起请求
- DNS解析
- SSL/TLS 终止:如果 Ingress 控制器配置了 SSL/TLS 终止,即在 Ingress 控制器上进行 SSL/TLS 解密操作,那么请求将被解密并转发给后端服务。这个步骤在 Ingress 控制器接收到请求后,但在路由请求到后端服务之前。
- Ingress 控制器的健康检查:有时候 Ingress 控制器会对后端服务进行健康检查,以确保只有健康的后端服务才会接收流量。这个检查通常是通过发送健康检查请求并检查响应来完成的。
- DNS 缓存:在进行 DNS 解析之前,系统可能会先查找本地 DNS 缓存,以查找以前解析过的域名对应的 IP 地址。如果找到了缓存,就不需要再进行 DNS 解析,直接使用缓存的 IP 地址。
- DNS 解析器选择:在进行 DNS 解析时,系统可能会选择使用不同的 DNS 解析器。这可能是本地操作系统的默认解析器,也可能是特定的 DNS 服务器(如 Google Public DNS、Cloudflare DNS 等)。
- DNS 请求转发:如果本地解析器无法解析域名,它可能会将 DNS 请求转发给其他上游 DNS 服务器,直到找到能够解析域名的服务器为止。
- 域名搜索列表:在进行 DNS 解析时,系统可能会使用域名搜索列表(Search Domain List),将未指定完全限定域名的主机名转换为完整的域名。这个列表通常包含了本地域和其他配置的域名。
- 发送请求到集群
- ingress控制器处理请求
- 匹配到合适的service
- 找到合适的pod
- 后端处理
- 结果响应
配置和存储
configMap
1 | |
example
创建一个 db.txt && redis.txt
1 | |
1 | |
gitlab的安装
harbor
docker的镜像仓库
sonarQube
代码检查
jekins
自动化构建、测试、部署和发布软件。
代码检查;Jenkins 可以在构建或部署过程中发送通知(如邮件、Slack 消息),及时告知团队成员构建和部署的状态·
- 插件安装
- token
- gitlab
- sonarQube
- node and label parameter
- kubernetes

实战
cicd流程

项目架构

helm
helm是什么
Helm 是 Kubernetes 的包管理器,主要用于简化和自动化 Kubernetes 应用的部署、升级和管理。Helm 提供了一套命令行工具和 API,用于与 Kubernetes 集群进行交互,管理 Kubernetes 资源的生命周期。
Helm 和 Charts 的关系
Chart 是 Helm 的基本单元:
- Helm 使用 Chart 来定义和打包 Kubernetes 应用程序。
- 一个 Chart 包含了 Kubernetes 应用程序的所有必要资源定义文件和配置文件。
Helm 管理和安装 Charts:
- Helm 提供命令行工具来安装、升级和管理 Charts。
- 当用户执行
helm install命令时,Helm 会将指定的 Chart 部署到 Kubernetes 集群中。
Chart 的组织结构:
一个 Chart 是一个目录结构,包含一组预定义的文件和子目录。典型的 Chart 结构如下:
1
2
3
4
5
6plaintext复制代码mychart/
├── Chart.yaml # Chart 的基本信息(名称、版本、描述等)
├── values.yaml # 默认的配置值
├── charts/ # 依赖的子 Charts
├── templates/ # Kubernetes 资源的模板文件
└── README.md # Chart 的文档
使用 values.yaml 文件进行配置:
Chart 通常包含一个
values.yaml文件,用于定义默认的配置参数。用户可以在安装 Chart 时覆盖这些参数,以定制应用的部署。例如:
1
2
3bash
复制代码
helm install my-release mychart --set image.tag=v1.2.3
- Charts 的版本管理和仓库:
Charts 可以版本化,并发布到 Helm 仓库中。
用户可以从官方或自定义的 Helm 仓库中拉取 Charts 进行部署。例如:
1
2
3bash复制代码helm repo add stable https://charts.helm.sh/stable
helm repo update
helm install my-release stable/nginx
简单使用
- 查看仓库
1 | |
- 查找chart
1 | |
- 查看charts详细信息
1 | |
- 安装charts
1 | |
- 更新
1 | |
- 回滚
1 | |
- 查看历史
1 | |
- 删除 relese
1 | |
- 查看已删除的
1 | |
k8s的调度器
kube-scheduler根据特定的调度算法和调度策略将pod调度到合适的Node上,这是一个独一无二的二进制程序,启动会一直监听api-server的指令
预选
优选
k8s的亲和度调度
负载均衡
在负载均衡中,四层(L4)和七层(L7)分别指的是OSI(Open Systems Interconnection)模型中的不同层级,用于描述网络通信系统的结构和功能。下面是对四层和七层的详细解释:
四层负载均衡(L4 Load Balancing)
四层负载均衡基于OSI模型中的传输层(第四层)。传输层主要负责端到端的通信,包括TCP(Transmission Control Protocol)和UDP(User Datagram Protocol)等协议。四层负载均衡器通过以下方式分发流量:
- IP地址和端口号:四层负载均衡器根据客户端和服务器的IP地址和端口号来决定如何分发流量。
- 协议信息:四层负载均衡器可以基于TCP/UDP协议的信息来进行负载均衡。
优点:
- 性能高,因为它只需要检查网络和传输层的报头,不需要深入检查数据包的内容。
- 配置和管理相对简单。
缺点:
- 灵活性差,无法基于应用层的数据内容进行智能路由。
- 不能执行复杂的流量控制策略,如基于URL、Cookie或HTTP头的负载均衡。
常见使用场景:
- 高性能需求的环境,如简单的Web服务器、游戏服务器等。
七层负载均衡(L7 Load Balancing)
七层负载均衡基于OSI模型中的应用层(第七层)。应用层处理高级别的应用服务,如HTTP、HTTPS、FTP等协议。七层负载均衡器通过以下方式分发流量:
- 内容检查:七层负载均衡器可以检查数据包的内容,包括URL、HTTP头、Cookie、表单数据等。
- 应用级策略:它可以基于具体的应用级数据进行流量分发,例如将某些URL路径的请求定向到特定的服务器。
优点:
- 灵活性高,可以基于具体的应用内容和高级策略进行负载均衡。
- 支持更细粒度的流量控制和安全策略。
缺点:
- 性能相对较低,因为需要深入检查数据包的内容。
- 配置和管理较复杂,需要了解应用层协议和应用的具体需求。
常见使用场景:
- 需要智能路由的环境,如复杂的Web应用、API服务、微服务架构等。